Computational Perception
Sentiment analysis of Urdu poetry (اردو شاعری) with full-diacritic restoration
This project developed a comprehensive Natural Language Processing (NLP) system for sentiment analysis of Urdu poetry with full-diacritic restoration. The research addressed the critical challenge of processing resource-poor languages by leveraging cross-linguistic similarities between Urdu and Arabic scripts.
The project employed transformer-based architectures (BERT) and advanced diacritization techniques to improve sentiment analysis accuracy for Urdu poetry. By utilizing an established Arabic corpus for diacritization and implementing multiple CAMeLBERT models, significant improvements in sentiment classification accuracy were achieved while addressing the unique challenges of abjad-based language processing.
Table of Contents
- Main Goals
- Related Work
- Experimental Platform
- Methodology
- Results
- Discussion and Limitations
- Conclusion and Future Work
- References
Main Goals
- Develop sentiment analysis for resource-poor languages
- Address the challenge of limited linguistic resources for Urdu
- Implement cross-linguistic diacritization using Arabic corpus
- Improve sentiment classification accuracy through diacritic restoration
- Implement transformer-based NLP architecture
- Utilize BERT models for sentiment analysis
- Apply CAMeLBERT variants for Arabic language processing
- Develop comprehensive evaluation framework for accuracy assessment
- Create experimental platform for language processing
- Design hardware-accelerated processing system using NVIDIA Jetson Nano
- Implement software pipeline for diacritization and sentiment analysis
- Establish reproducible methodology for cross-linguistic NLP research
Introduction
The Natural Language Processing (NLP) technique of Sentiment Analysis (SA) gives computers the ability to decipher a given piece of text and categorize it into whether the sentiment is positive, negative, or neutral. This plays a key role in understanding social media, reviews and news, and sorting given text by opinion and emotion in general. Computers are perceptibly unintelligent, and by utilizing transformer-based architectures and their derivatives (i.e., BERT – Bidirectional Encoder Representations from Transformers)[1], we can enter a new era of natural language workloads, namely, Natural Language Understanding (NLU), improving on perception further.
While SA is largely developed for resource rich languages (i.e., English, French, German), it often lacks for languages which are resource poor (i.e., Urdu, Swahili, Vietnamese, Hindi). Even though these resource poor languages are spoken by a large population, there is less textual and auditory data available on the internet for them. Due to this, it is hard to train machine learning architectures like BERT on properly computing NLU tasks. Namely, SA is one task that suffers from this lack of data.
The Urdu language is the primary language under consideration in this text. Urdu suffers from a lack of written text available on the internet which makes it difficult to properly categorize given text into positive, negative, or neutral categories. Furthermore, as an abjad-based language, diacritics, short vowels added onto main letters, play an important role in the meaning of words. As most internet texts remove these diacritics for easier readability, word meaning must often be inferred by the reader. This creates many problems for BERT to be able to properly gauge the meaning, and sentiment by extension, of a given phrase as computers lack the level of perception that human readers possess. By using another abjad-based language like Arabic as a base which is resource rich comparatively, we propose a method of introducing diacritics fully into a given piece of Urdu text with the novel application of categorizing chosen Urdu poetry as positive or negative.
Related Work
The BERT Transformer-based Architecture
As mentioned, the BERT transformer-based architecture is used in this work as a primary method of evaluating Urdu poetry for its sentiment. BERT, or Bidirectional Encoder Representations from Transformers, are a major improvement over previous natural language models. More specifically, the work done in sequence modeling and transduction problems related to natural language and machine translation tasks was dependent on recurrent neural networks (RNN) and long-short term memory (LSTM)[1]; the high-level implementation is shown in Figure 1. These previous methods were unable to parallelize tasks, took a long time with sequential computation due to recurrence, were susceptible to vanishing gradients, which is the loss of information due to the backpropagation process in neural networks, and were unable to capture meaningful information in a given text for words that were distant from each other.
Transformer architectures were introduced in 2017 by researchers at Google[1] as a way to solve these problems. The key focus of this architecture was introducing a concept called self-attention[1] (shown in Figure 2). The main change was taking out the recurrent feedback loops allowing inputs to interact with one another.
These improvements over the previous RNN implementations allows NLP researchers to branch into this new era of NLU, allowing techniques like SA to function and operate on our Poetry strings. BERT essentially trains the neural network bidirectionally simultaneously instead of either left to right, right to left, or a combination of both. This, at an abstracted high-level, increases our accuracy in the SA process.

Diacritization
In order to properly diacritize text for Urdu, we use a language agnostic diacritization model introduced by Belinkov and Glass[3] as the underlying base. The authors use RNNs to achieve this functionality with the specific LSTM superset introduced above. While transformer-based architectures may have an added performance benefit due to parallelization, it is not integral for computationally meaningful results. Arabic is used as a functional example throughout their text and will be used in this text to draw connections to Urdu as both abjad languages share diacritic foundations.
An added diacritization model layer is used which lies upon the base model introduced by Belinkov and Glass[3]. This is the main model that we have access to and interact with at the terminal level. Introduced by Inoue et al. (2021),
As mentioned previously, diacritics (short vowels) are often omitted from abjad languages for easier readability in internet texts, leaving only consonant sounds. The reader must then infer the vowels based on the sentence context. This is easier for humans to do but extremely difficult for computers as they lack the necessary perception. Figure 3 below shows how one word in Arabic, علی, without diacritics is ambiguous but gains meaning when they are included. More specifically, inclusion of each of the shown diacritics narrows the meaning down to knowledge, flag, taught, and known respectively.

The same applies for the Urdu language. If we consider the word اس, the added diacritics zaber and paish create a meaning corresponding to the English translation of this and that respectively. There are many diacritics to be considered, so for brevity, they will not be covered in totality but rather described when relevant throughout this text.
| Urdu Word | English Translation | Diacritic Added |
|---|---|---|
| اِس | this | Zaber |
| اُس | that | Paish |
Table 1. Summary of Urdu Diacritics added to اس
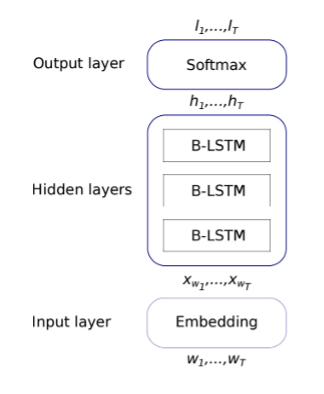
The diacritization model presented treats each letter within the given text as a sequence classification task. Each letter has a corresponding Buckwalter transliteration (discussed more in Section 2.3 below). The neural network topology presented by Belinkov and Glass is shown below in Figure 4. As a sentence is input into the network, each word is split up into its constituent characters. These characters are trained through the network with the corresponding Buckwalter transliteration. At the output, we obtain a probability distribution for each word and its added diacritic counterparts. The highest probability for each word is chosen and put back in the same position within the output sentence.
Buckwalter Transliteration
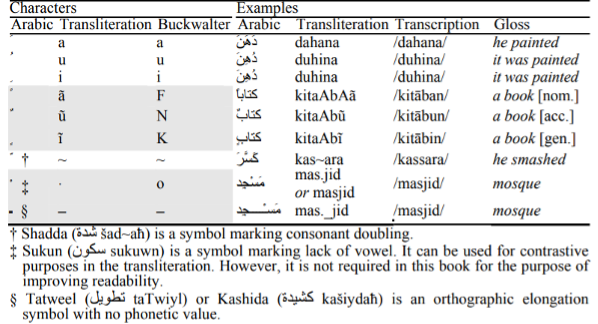
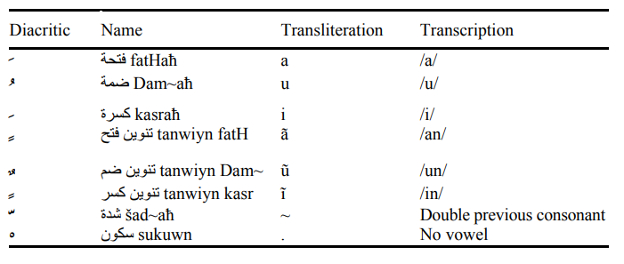
The Buckwalter Transliteration scheme provides a standardized method to encode abjad-based letters. While the transliteration scheme focuses on Arabic, it can be extended to Urdu as well. Figure 5 below gives the full list of diacritic markings from Arabic and their Buckwalter counterparts (Figure 6 has a more focused/simplified view).
Experimental Platform
Hardware
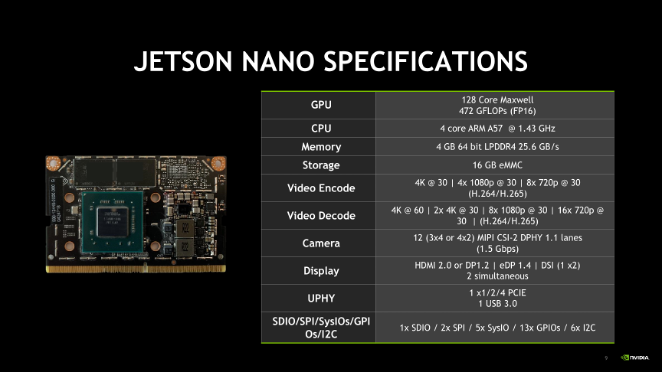
The NVIDIA Jetson Nano (shown in Figure 7, with detailed specifications in Figure 9) will be the core accelerator component that will be required by the diacritization and sentiment analysis processes. While not integral for computationally meaningful results, it helps to reduce the time that training will take specifically in diacritization with Buckwalter transliteration. BERT is largely pretrained and will only benefit from acceleration marginally; comparison between hardware acceleration in NLP tasks is a worthwhile discussion to be had but is not the focus of this study. Figure 8 below shows hardware connections for our setup. The NVIDIA Jetson Nano is connected to a pfSense managed network through gigabit ethernet, powered by a 5 Volt / 5 Amp supply, connected through USB for serial connection (used for initial setup and failover – SSH connectivity is used primarily), an added PWM heatsink fan, and a 128 GB SDXC card running the operating system.


Software
Operating System and Drivers
The NVIDIA Jetson Nano is configured to run the Ubuntu-derived distribution Jetson Linux (L4T). Additionally, the JetPack Software Development Toolkit (SDK) which properly utilizes the hardware functionality of the Nano (i.e., the CUDA cores) is installed.
CURRENNT – RNN CUDA Enabled Library
Diacritization tends to be a computationally intensive task which requires multiple processing units adding diacritics to letters defined through Buckwalter transliteration. CURRENNT utilizes NVIDIA Graphics Processing Units (GPUs) to parallelized deep LSTMs[7].
BERT Diacritizer
This python framework will the primary means to diacritize the Urdu text. It is an automated diacritization system. It works by utilizing the software listed above in 3.2.1 and 3.2.2. The CURRENNT library (3.2.2) is not used directly but is a building block for this BERT diacritizer; therefore, it is mentioned above. The framework operates under a standard training, testing, and validation paradigm with numerous adjustable parameters. It can be found here.
Tashkeela Arabic Diacritization Corpus
Collection of more than 75 million Arabic words from 97 books, mainly Islamic classical books or from the internet using web-crawling processes[9]. This corpus has variation in both modern and classical Arabic. The BERT Diacritizer mentioned above (3.2.3) utilizes this corpus to perform the automated diacritization process. It can be found here.
PyTorch ML Framework and BERT
In order to implement the Transformer-based BERT model, we utilize the PyTorch Machine Learning Framework. The transformers library is imported into Python (operating in Jupyter Lab – described in more detail below in 3.2.6) and pipeline is used on four pretrained multilingual BERT models from CAMeL Lab. More specifically, each of these models targets Modern Standard Arabic (MSA), Mixed Arabic (MIX), Classical Arabic (CA), and Dialectal Arabic (DA) to analyze sentiment. All of these are hosted through Hugging Face repository and are labeled/linked as follows:
-
CAMeLBERT MSA: CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment found here.
-
CAMeLBERT MIX: CAMeL-Lab/bert-base-arabic-camelbert-mix-sentiment found here.
-
CAMeLBERT CA: CAMeL-Lab/bert-base-arabic-camelbert-ca-sentiment found here.
-
CAMeLBERT DA: CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment found here.
Python, Jupyter Lab, and Relevant Libraries
Python 3 was used in both the BERT Diacritizer and in Jupyter Lab. The Jupyter Lab environment served as the sentiment analysis and web-crawling testbench. The libraries are described and linked below.
####### Sentiment Analysis
| Library | Description |
|---|---|
| PyTorch | Open-source machine learning framework where BERT is used for inference on sentiment output. Additionally, it is used as the backend for the BERT Diacritizer for both training and inference. |
| Transformers | Provides APIs for pretrained models. Many models are supported, included the one used in this text: BERT. Specifically, the pipeline import is used for sentiment analysis with CAMelBERT. |
| NumPy | Basis for scientific computing by providing comprehensive math functions. Used throughout the testbench for various computations. |
| Pandas | Used for data representation and organization (with DataFrames). |
| Matplotlib | Library for creating visualizations of data, specifically our DataFrames. Used to generate graphs. |
| Seaborn | Another data visualization library. Used in conjunction with Matplotlib to simplify graph representation. |
Table 2. Sentiment Analysis specific Python libraries.
####### Web Crawling
| Library | Description |
|---|---|
| BeautifulSoup | Used for automating parsing of web pages for specific data. |
| Requests | HTTP processing library. For interpreting HTML tags in web pages. Used in conjunction with BeautifulSoup. |
Table 3. Web Crawling specific Python libraries.
Google Translate
The Google Translation Engine was used as a primary objective means to translate non-diacritized Urdu to English for reader understandability in this text.
Methodology
The general methodology for our task is described below in Figure 10. Urdu poetry will be chosen objectively based on categorization of positive and negative sentiment from the poetry website linked here. This website was chosen for its categorized poems and ease of use in the website scrubbing process. The main categories chosen for positive and negative sentiment were funny and sad poems respectively. SA will be performed on Python within JupyterLab.
| Step | Description |
|---|---|
| 0 | Initially, we must grab poem samples for each funny and sad category from the website linked. An odd number of 19 was chosen as this was the maximum that the scrubbing tool was able to bring in. |
| 1 | We use CAMeLBERT for our pretrained SA model on MIX, MSA, CA, and DA. These were chosen for a broad diversity in language style that may fit the style of the given poetry samples. Each poetry sample in the funny and sad poem category was run through each of these models to generate a label of “positive,” “negative,” or “neutral” along with the accuracy percentage for each label. |
| 2 | The web scrubbing tool was used to collect 150 samples at random from each web page for training the Tashkeela D3 model. The number of epochs was reduced from 1000 originally to 100 for NVIDIA Jetson Nano Hardware Limitations on the training process. |
| 3 | We run our original 19 poem samples for each category through BERT Diacritizer prediction on the Tashkeela D3 model. |
| 4 | Any jumbled diacritics (which have no sensical location) are removed to make prediction size (number of sentences in the prediction output) equal to the test size (number of sentences in the test input). This is used in the subsequent step for Diacritic Error Rate (DER) and Word Error Rate (WER) evaluation. |
| 5 | Newly diacritized poem samples for each category are now run through diacritization evaluation to generate values of WER and DER for both case-endings and no case-endings. WER and DER are important error rate calculations used throughout abjad-based text [10]. Case-endings refer to when the end letter in the sentence (or character array in general) has an added diacritic. Conversely, no case-endings refer to when the end letter in the sentence does not have an added diacritic. |
| 6 | Newly diacritized poem samples for each category are run through each CAMeLBERT model again, generating new labels and accuracy percentage scores. |
| 7 | Results of Step 1 and 6 are compared on label and accuracy. Also, DER and WER statistics are evaluated from Step 5. |
Table 4. Methodology in Detail.
Results
Poetry Sample Collection
The randomized poetry samples scrubbed from the poetry website described in the Methodology section are tabulated below. The collection was split into funny and sad poetry as described. Note, since these were collected at random, some English Translations may be non-sensical or ill-fitting of an academic context; nevertheless, to ensure sampling is done at random, we have included them. Additionally, as Google Translate is being used for the English translation, they may be incorrect; this is permissible given the context of the paper which focuses on the base language sentiment retrieval. English translation is based on non-diacritized sample.
| Index | Urdu Poem Sample | English Translation |
|---|---|---|
| 0 | دھوبی کا کتا ہوں گھر کا نہ گھاٹ کابیگم بارہا کہہ چکیں دشمن ہوں اناج کا | I am the dog of the washerman. |
| 1 | کبھی دادی لگتی ھے کبھی نانی لگتی ھے ماڈل ھے پرانہ مگر گڑیا جاپانی لگتی ھے | Sometimes she looks like a grandmother, sometimes she looks like a grandmother, the model is old, but the doll looks Japanese. |
| 2 | وہ جب ناراض ہوتے ہیں تو "کانپیں ٹانگ" جاتی ہیں کسی سے کچھ نہ کہتے ہیں تو "کانپیں ٹانگ" جاتی ہیں | When they are angry, they tremble. When they do not say anything to anyone, they tremble. |
| 3 | اتنا دبلا ہو گیا ہوں صنم تیری جدائی سےکھٹمل بھی کھینچ لیتے ہیں مجھے چارپائی سے | I have become so thin. Sanam pulls me out of bed with your separation. |
| 4 | ہم نے مانا کہ رپلائی نہ کرو گے تم لیکنٹرائی کرتے رہیں گے ہم بھی بلاک ہونے تک | We agreed not to reply. You will keep trying until we are blocked. |
| 5 | جس بھی شادی میں جاتا ہوںکسی نہ کسی لڑکی سے پیار ہوجاتا ہے | Every time I go to a wedding, I fall in love with some girl. |
| 6 | اگر تمہارے وعدے نہ ہوتے کچےتو اب ہوتے ہمارے دو بچے | If it weren't for your promises, we would have two children now. |
| 7 | یہ اتوار نہیں آساں بس اِتنا ہی سمجھ لیجئےاِک کپڑوں کا دریا ہے اور دھوکے سُکھانا ہے | This Sunday is not easy, just understand that there is a river of clothes and deception to dry. |
| 8 | گھر میں اگر کوئی عقل کی بات کردوتو سب یہی پوچھتے ہیں | This is what everyone in the house asks if you talk about common sense. |
| 9 | افریقہ میں ایک کالے شوہر نےاپنی کالی بیوی کو کالی رات میں | In Africa, a black man killed his black wife in the dark night. |
| 10 | ایک سال سے میں شادی کے لئے جو وظیفہ پڑھ رہا تھاافسوس! آج کسی نے بتایا کہ وہ سعودی عرب کا قومی ترانہ ہے | I have been studying marriage allowance for over a year. Sorry! Someone said today that it is the national anthem of Saudi Arabia. |
| 11 | ہم کو کرنٹ لگا ھے چاہت کا ہمارے عشق کے بٹن شا ٹ ہیں | We are electrocuted, our love buttons are shots. |
| 12 | سالوں بعد جب ملیں گے تو کیا کہیں گےہم ایک دوجے کو کسی اور کا کہیں گے | What will we say when we meet years later? We will call each other someone else's. |
| 13 | بیگم کو چڑھا ھے شوق سیلفی کھچوانے کا کیمرے کے آگے منہ اپنا بگاڑنے نبانے کا | Begum is obsessed with taking selfies and pretending to be in front of the camera. |
| 14 | ہم نے مانا کہ رپلائی نہ کرو گے تم لیکن ٹرائی کرتے رہیں گے ہم بھی بلاک ہونے تک | We agreed that you will not reply, but we will keep trying until we are blocked. |
| 15 | سب جھاڑ پھونک سیکھ گئے شیخ جی سے ہم مرغے کو ذبح کرتے ہیں الٹی چھری سے ہم | We have all learned to blow the whistle. From Sheikh Ji we slaughter the rooster with the inverted knife. |
| 16 | ہے کامیابیٔ مرداں میں ہاتھ عورت کا مگر تو ایک ہی عورت پہ انحصار نہ کر | Success is a woman's hand in men, but do not rely on a single woman. |
| 17 | صرف محنت کیا ہے انورؔ کامیابی کے لئے کوئی اوپر سے بھی ٹیلیفون ہونا چاہئے | Just work hard Anwar - for success there should be a telephone from above. |
| 18 | آم تیری یہ خوش نصیبی ہے ورنہ لنگڑوں پہ کون مرتا ہے | Mango is your good fortune, otherwise who dies on the lame. |
Table 5. Funny poetry samples randomly scrubbed from website.
| Index | Urdu Poem Sample | English Translation |
|---|---|---|
| 0 | تمہاری منتظر یوں تو ہزاروں گھر بناتی ہوںوہ رستہ بنتے جاتے ہیں کچھ اتنے در بناتی ہوں | Waiting for you, I build thousands of houses, they become roads, I build so many doors. |
| 1 | ہم انہیں وہ ہمیں بھلا بیٹھےدو گنہ گار زہر کھا بیٹھے | We forgot about them and ate the poison of two sinners. |
| 2 | وہ شخص حسن اپنا دکھا کر چلا گیادیوانہ مجھ کو اپنا بنا کر چلا گیا | That person showed his beauty and left. The madman made me his own and left. |
| 3 | اے نگاہ دوست یہ کیا ہو گیا کیا کر دیاپہلے پہلے روشنی دی پھر اندھیرا کر دیا | O friend of the eye, what has become of this? |
| 4 | رواں دواں ہے زندگی چراغ کے بغیر بھیہے میرے گھر میں روشنی چراغ کے بغیر بھی | Life goes on without a lamp in my house without a lamp. |
| 5 | وہ ہنس ہنس کے وعدے کیے جا رہے ہیںفریب تمنا دیے جا رہے ہیں | They are being promised laughter, deception is being given. |
| 6 | چشم نم پر مسکرا کر چل دیئےآگ پانی میں لگا کر چل دیئے | They smiled at the damp eyes and walked away. |
| 7 | چاہت کی اذیت رہائی نہ دے گیکہ بچنےکی راہ بھی دکھائی نہ دےگی | Don't let go of the pain of lust or you will not find a way to escape. |
| 8 | کون جیتا کون ہارا یہ کہانی پھر سہیہوگا کیسے اب گزارہ یہ کہانی پھر سہی | Who won, who lost, this story will endure again. |
| 9 | ہر آئنے میں ترے خد و خال آتے ہیںعجیب رنج ترے آشنا اٹھاتے ہیں | In every mirror there are tears and strange sorrows and acquaintances. |
| 10 | شکستہ دل تھے ترا اعتبار کیا کرتےجو اعتبار بھی کرتے تو پیار کیا کرتے | They were broken-hearted. |
| 11 | محبت کا حوالا ہی نہیں ہے چراغوں میں اجالا ہی نہیں ہے | There is no reference to love, there is no light in the lamps. |
| 12 | آج تیرا چہرہ نہیں رہا قابلِ دید احسن کبھی تم بھی ہوتے تھے ہلالِ عید احسن | Today, your face is no longer visible. Ahsan, you used to be the crescent of Eid-ul-Fitr. |
| 13 | آج تیرا چہرہ نہیں رہا قابلِ دید کبھی تم بھی ہوتے تھے ہلالِ عید | Today your face is no longer visible. You used to be the crescent of Eid. |
| 14 | ہجوم غم میں کس زندہ دلی سےمسلسل کھیلتا ہوں زندگی سے | How lively I play with life in the crowd of grief. |
| 15 | یاد یہ کس کی آ گئی ذہن کا بوجھ اتر گیاسارے ہی غم بھلا گئی ذہن کا بوجھ اتر گیا | Remember, the burden of one's mind has come down, all the grief has been forgotten, the burden of mind has come down. |
| 16 | شام غم ہے تری یادوں کو سجا رکھا ہےمیں نے دانستہ چراغوں کو بجھا رکھا ہے | The evening is sad. I have decorated the wet memories. I have deliberately turned off the lights. |
| 17 | ابھی خاموش ہیں شعلوں کا اندازہ نہیں ہوتامری بستی میں ہنگاموں کا اندازہ نہیں ہوتا | They are silent now. You don't know the flames. You don't know the commotion in your town. |
| 18 | خود پکارے گی جو منزل تو ٹھہر جاؤں گاورنہ خوددار مسافر ہوں گزر جاؤں گا | She will cry out for the destination if she stays, otherwise she will be a self-sufficient traveler. |
Table 6. Sad poetry samples randomly scrubbed from website.
Diacritization
BERT Diacritizer Prediction Output
The output of running each of the poetry samples for both funny and sad poetry samples through the BERT Diacritizer, with subsequent cleanup, is tabulated below. The important distinction to make with these results (in both cases even if you lack or do not lack linguistic familiarity) is the inclusion of diacritics onto each space delimited word.
| Urdu Poem Sample (Non-Diacritized) | Urdu Poem Sample (Diacritized) |
|---|---|
| تمہاری منتظر یوں تو ہزاروں گھر بناتی ہوںوہ رستہ بنتے جاتے ہیں کچھ اتنے در بناتی ہوں | تمہَاْرُیُ منتَظَرْ یوَّںَ توَ َہُزاَرَوٍں ُگْھَرَ َبٍناَتَیَ ہَوَںُوُہ رسَتِہَ بُنُّتےَ َجِاِتے ہَیَںِ َکُچھِ ْاُتنِے َدِرَ بنَاِتْیُ ہُوْںِ |
| ہم انہیں وہ ہمیں بھلا بیٹھےدو گنہ گار زہر کھا بیٹھے | ہَمْ ُاُنہیں َوَہَ َہمیںَّ بِھِلُّا ِبَّیَٹَھےدو َگِنْہ َگَاَر َزْہِر َکھاْ َبْیِٹِھےَ |
| وہ شخص حسن اپنا دکھا کر چلا گیادیوانہ مجھ کو اپنا بنا کر چلا گیا | وَہَ ِشُخصَ َحْسِن َاَّپنَا ِدَکھا َّکُر َچْلِا َگَیْاِدِیوَاْنَہ َمُجھَ َکوٌ اپَّنا بَنا َکرَ چلْاَ ْگُیاَ |
| اے نگاہ دوست یہ کیا ہو گیا کیا کر دیاپہلے پہلے روشنی دی پھر اندھیرا کر دیا | اُےَ ْنٍگاَہ َدوَسِتْ ُیہَ ِکیاُ َہِّوُ گَیْا َکَّیَا کْرُ َدِیِّاپَہلَے َپَہْلُے َرِوًّشنیَ ِدَی پھَّرُ اَنْدُھیَرِاَ کَرَ دیاْ |
| رواں دواں ہے زندگی چراغ کے بغیر بھیہے میرے گھر میں روشنی چراغ کے بغیر بھی | رَوَاَں دَوْاٌں َہْےُ زٌندَگْیُ چراغ کے بغیر بھیہے میرے گھر میں روشنی چراغ کے بغیر بھی |
| وہ ہنس ہنس کے وعدے کیے جا رہے ہیںفریب تمنا دیے جا رہے ہیں | وَہْ ہنسَ ِہنِس کےَ ُوَعَدے کَیَےْ ِجا ْرِہے ْہَیںِفریب تمنا دیے جا رہے ہیں |
| چشم نم پر مسکرا کر چل دیئےآگ پانی میں لگا کر چل دیئے | چِشَمَّ ُنْم َپْرَ ُمَسکرْاُ ْکرَ چَل دُیَئےِآُگ َپَانِیَ ُمْیں لَگْاِ کرَ چلَّ ُدیَئْےَ |
| چاہت کی اذیت رہائی نہ دے گیکہ بچنےکی راہ بھی دکھائی نہ دےگی | چَاْہُتُ کی اَذُیَت رہَاْئی نَّہ ِدَےُ گَیِکْہُ ُبچُنَےکَی ًراِہْ َبَھِی َدُکَھاَئْیُ ُنہُ َدَّےٌگی |
| کون جیتا کون ہارا یہ کہانی پھر سہیہوگا کیسے اب گزارہ یہ کہانی پھر سہی | کونَّ َجِیتا کَوْن َہِاَرا یَّہَ کہُاٌّنیِ ْپُھَر سَہَّیُہوَگا َکْیَسُے َاْبَ گَزارَہَ َیہِ ِکہاْنَیْ ُپھر َسِہَّیُ |
| ہر آئنے میں ترے خد و خال آتے ہیںعجیب رنج ترے آشنا اٹھاتے ہیں | ہر َآْئُنُے میَںُ ْتَرَےُ خِد وَ َخال ْآُتْےِ ہَیْںعَجُیبَ رُنَّجِ ًترےِ اْ ِْٓ َشنِا اٹَھَاْتے ْہَیَںَ |
| شکستہ دل تھے ترا اعتبار کیا کرتےجو اعتبار بھی کرتے تو پیار کیا کرتے | شَکستہَ ْدلَ ِتَھے تَرَا اعُتْبِارَ َکِّیاِ َکرٍتےجوَ َاعَتِباَرْ ٍبھی َکَرْتَےَ تِوْ پَیَاِرِ کیاَ کرَتْےِ |
| محبت کا حوالا ہی نہیں ہے چراغوں میں اجالا ہی نہیں ہے | مَحَبْتُ ُکا حُوَّالا َّہِیَ ُنہَیِںَ ُہےَ ْچٍراِغْوَں ُمَیَّںٍ اِجَالًا ہِیْ َنَہِیںْ ِہےِ |
| آج تیرا چہرہ نہیں رہا قابلِ دید احسن کبھی تم بھی ہوتے تھے ہلالِ عید احسن | آِج ْتُیْرَاِ چہرَہُ َنہِیْں ُرْہَاِ قَابلِ دَیدَ احَسَنَ کِبَھیِ َتَم َبِھَی ہوّتُے َتْھَے ہَلَاَل َعْیَدُ ُاحسّن |
| آج تیرا چہرہ نہیں رہا قابلِ دید کبھی تم بھی ہوتے تھے ہلالِ عید | آَجَ َتیرُاْ ِچٌہرِہِ ْنَہیِںِ رَہْا ُقَاْبِل ْدِیدُ َکْبِھیَ تَم َبھی َہوَتےَ ُتٌھےِ َہلاَلْ ِعید |
| ہجوم غم میں کس زندہ دلی سےمسلسل کھیلتا ہوں زندگی سے | ہَجومَّ غُّم مْیَںَ ُکسَ ْزنَدُہَ دَلْی سْےَمسِلسل َکھْیَلْتُا ہَّوِں زُنَدُّگیِ ِسے |
| یاد یہ کس کی آ گئی ذہن کا بوجھ اتر گیاسارے ہی غم بھلا گئی ذہن کا بوجھ اتر گیا | یَاَدَّ َیہِ َکْسُ کِی َآْ َگْئی ِذَہْنِ ِکاَ ْبُوجَھ َاْتَر َگْیٍاسَاَرےَ ہی َغم بھْلاَ ْگئَیْ ُذْہنَ َکَا َبُوجھ َّاْتُر گیَاَ |
| شام غم ہے تری یادوں کو سجا رکھا ہےمیں نے دانستہ چراغوں کو بجھا رکھا ہے | شامَ غم َہِےُّ تَرْیً یاِدَوْںِ کٍو سجِاَ ْرِکھا َّہِےمَیں َّنْےَ دِانَستہَّ َچِراَغِوْں کوَ ِبَجھَا رکَھَاَ ہِےِ |
| ابھی خاموش ہیں شعلوں کا اندازہ نہیں ہوتامری بستی میں ہنگاموں کا اندازہ نہیں ہوتا | ابھَّیْ َخامَوشْ َہِّیَں ِشعَلَوںِ َکاَ ٍانداَزَہ نِہَیںَ ہوتَاَمریِ َبَستی َمَیں َہْنِگٍّاموںُ ِکَا َانَداِزَہ َنِہِیں ہَوِتْا |
| خود پکارے گی جو منزل تو ٹھہر جاؤں گاورنہ خوددار مسافر ہوں گزر جاؤں گا | خُوْدُ پکاَرَےَ ْگَی َجْو َمَّنزَلْ ًتو َٹَھَہرِ َجاَّؤِں َگْاوَرنہُ َخِّوَددُاَر ًمسافرَ َہَّوَںُ گَزَرِ َجاَؤُں َگِّاُ |
Table 7. Non-Diacritized (ND) to Diacritized (D) Funny Urdu Poetry Samples.
| Urdu Poem Sample (Non-Diacritized) | Urdu Poem Sample (Diacritized) |
|---|---|
| تمہاری منتظر یوں تو ہزاروں گھر بناتی ہوںوہ رستہ بنتے جاتے ہیں کچھ اتنے در بناتی ہوں | تمہَاْرُیُ منتَظَرْ یوَّںَ توَ َہُزاَرَوٍں ُگْھَرَ َبٍناَتَیَ ہَوَںُوُہ رسَتِہَ بُنُّتےَ َجِاِتے ہَیَںِ َکُچھِ ْاُتنِے َدِرَ بنَاِتْیُ ہُوْںِ |
| ہم انہیں وہ ہمیں بھلا بیٹھےدو گنہ گار زہر کھا بیٹھے | ہَمْ ُاُنہیں َوَہَ َہمیںَّ بِھِلُّا ِبَّیَٹَھےدو َگِنْہ َگَاَر َزْہِر َکھاْ َبْیِٹِھےَ |
| وہ شخص حسن اپنا دکھا کر چلا گیادیوانہ مجھ کو اپنا بنا کر چلا گیا | وَہَ ِشُخصَ َحْسِن َاَّپنَا ِدَکھا َّکُر َچْلِا َگَیْاِدِیوَاْنَہ َمُجھَ َکوٌ اپَّنا بَنا َکرَ چلْاَ ْگُیاَ |
| اے نگاہ دوست یہ کیا ہو گیا کیا کر دیاپہلے پہلے روشنی دی پھر اندھیرا کر دیا | اُےَ ْنٍگاَہ َدوَسِتْ ُیہَ ِکیاُ َہِّوُ گَیْا َکَّیَا کْرُ َدِیِّاپَہلَے َپَہْلُے َرِوًّشنیَ ِدَی پھَّرُ اَنْدُھیَرِاَ کَرَ دیاْ |
| رواں دواں ہے زندگی چراغ کے بغیر بھیہے میرے گھر میں روشنی چراغ کے بغیر بھی | رَوَاَں دَوْاٌں َہْےُ زٌندَگْیُ چراغ کے بغیر بھیہے میرے گھر میں روشنی چراغ کے بغیر بھی |
| وہ ہنس ہنس کے وعدے کیے جا رہے ہیںفریب تمنا دیے جا رہے ہیں | وَہْ ہنسَ ِہنِس کےَ ُوَعَدے کَیَےْ ِجا ْرِہے ْہَیںِفریب تمنا دیے جا رہے ہیں |
| چشم نم پر مسکرا کر چل دیئےآگ پانی میں لگا کر چل دیئے | چِشَمَّ ُنْم َپْرَ ُمَسکرْاُ ْکرَ چَل دُیَئےِآُگ َپَانِیَ ُمْیں لَگْاِ کرَ چلَّ ُدیَئْےَ |
| چاہت کی اذیت رہائی نہ دے گیکہ بچنےکی راہ بھی دکھائی نہ دےگی | چَاْہُتُ کی اَذُیَت رہَاْئی نَّہ ِدَےُ گَیِکْہُ ُبچُنَےکَی ًراِہْ َبَھِی َدُکَھاَئْیُ ُنہُ َدَّےٌگی |
| کون جیتا کون ہارا یہ کہانی پھر سہیہوگا کیسے اب گزارہ یہ کہانی پھر سہی | کونَّ َجِیتا کَوْن َہِاَرا یَّہَ کہُاٌّنیِ ْپُھَر سَہَّیُہوَگا َکْیَسُے َاْبَ گَزارَہَ َیہِ ِکہاْنَیْ ُپھر َسِہَّیُ |
| ہر آئنے میں ترے خد و خال آتے ہیںعجیب رنج ترے آشنا اٹھاتے ہیں | ہر َآْئُنُے میَںُ ْتَرَےُ خِد وَ َخال ْآُتْےِ ہَیْںعَجُیبَ رُنَّجِ ًترےِ اْ ِْٓ َشنِا اٹَھَاْتے ْہَیَںَ |
| شکستہ دل تھے ترا اعتبار کیا کرتےجو اعتبار بھی کرتے تو پیار کیا کرتے | شَکستہَ ْدلَ ِتَھے تَرَا اعُتْبِارَ َکِّیاِ َکرٍتےجوَ َاعَتِباَرْ ٍبھی َکَرْتَےَ تِوْ پَیَاِرِ کیاَ کرَتْےِ |
| محبت کا حوالا ہی نہیں ہے چراغوں میں اجالا ہی نہیں ہے | مَحَبْتُ ُکا حُوَّالا َّہِیَ ُنہَیِںَ ُہےَ ْچٍراِغْوَں ُمَیَّںٍ اِجَالًا ہِیْ َنَہِیںْ ِہےِ |
| آج تیرا چہرہ نہیں رہا قابلِ دید احسن کبھی تم بھی ہوتے تھے ہلالِ عید احسن | آِج ْتُیْرَاِ چہرَہُ َنہِیْں ُرْہَاِ قَابلِ دَیدَ احَسَنَ کِبَھیِ َتَم َبِھَی ہوّتُے َتْھَے ہَلَاَل َعْیَدُ ُاحسّن |
| آج تیرا چہرہ نہیں رہا قابلِ دید کبھی تم بھی ہوتے تھے ہلالِ عید | آَجَ َتیرُاْ ِچٌہرِہِ ْنَہیِںِ رَہْا ُقَاْبِل ْدِیدُ َکْبِھیَ تَم َبھی َہوَتےَ ُتٌھےِ َہلاَلْ ِعید |
| ہجوم غم میں کس زندہ دلی سےمسلسل کھیلتا ہوں زندگی سے | ہَجومَّ غُّم مْیَںَ ُکسَ ْزنَدُہَ دَلْی سْےَمسِلسل َکھْیَلْتُا ہَّوِں زُنَدُّگیِ ِسے |
| یاد یہ کس کی آ گئی ذہن کا بوجھ اتر گیاسارے ہی غم بھلا گئی ذہن کا بوجھ اتر گیا | یَاَدَّ َیہِ َکْسُ کِی َآْ َگْئی ِذَہْنِ ِکاَ ْبُوجَھ َاْتَر َگْیٍاسَاَرےَ ہی َغم بھْلاَ ْگئَیْ ُذْہنَ َکَا َبُوجھ َّاْتُر گیَاَ |
| شام غم ہے تری یادوں کو سجا رکھا ہےمیں نے دانستہ چراغوں کو بجھا رکھا ہے | شامَ غم َہِےُّ تَرْیً یاِدَوْںِ کٍو سجِاَ ْرِکھا َّہِےمَیں َّنْےَ دِانَستہَّ َچِراَغِوْں کوَ ِبَجھَا رکَھَاَ ہِےِ |
| ابھی خاموش ہیں شعلوں کا اندازہ نہیں ہوتامری بستی میں ہنگاموں کا اندازہ نہیں ہوتا | ابھَّیْ َخامَوشْ َہِّیَں ِشعَلَوںِ َکاَ ٍانداَزَہ نِہَیںَ ہوتَاَمریِ َبَستی َمَیں َہْنِگٍّاموںُ ِکَا َانَداِزَہ َنِہِیں ہَوِتْا |
| خود پکارے گی جو منزل تو ٹھہر جاؤں گاورنہ خوددار مسافر ہوں گزر جاؤں گا | خُوْدُ پکاَرَےَ ْگَی َجْو َمَّنزَلْ ًتو َٹَھَہرِ َجاَّؤِں َگْاوَرنہُ َخِّوَددُاَر ًمسافرَ َہَّوَںُ گَزَرِ َجاَؤُں َگِّاُ |
Table 8. Non-Diacritized (ND) to Diacritized (D) Sad Urdu Poetry Samples.
BERT Diacritizer Evaluation
Diacritization metrics were obtained from the BERT Diacritizer accounting for DER and WER percentages. It looks at the original sample without diacritics (first column) and the sample with diacritics (second column). Additionally, the case endings narrow down these metrics as discussed previously in Methodology. All results are tabulated below.
| Including No Diacritic | Excluding No Diacritic | |||
|---|---|---|---|---|
| With Case Ending | Without Case Ending | With Case Ending | Without Case Ending | |
| DER % | 57.51 | 57.53 | 66.67 | 100.00 |
| WER % | 70.64 | 33.33 | 0.61 | 0.31 |
Table 9. Evaluation Metrics for Diacritization of Scrubbed Funny Poetry.
| Including No Diacritic | Excluding No Diacritic | |||
|---|---|---|---|---|
| With Case Ending | Without Case Ending | With Case Ending | Without Case Ending | |
| DER % | 59.73 | 59.86 | 75.00 | 0.00 |
| WER % | 75.16 | 36.02 | 0.93 | 0.00 |
Table 10. Evaluation Metrics for Diacritization of Scrubbed Sad Poetry.
DER was much higher when sentences were diacritized compared to the original for the funny poetry sample. The percent difference between sentences with case endings and without were 14.75% and 53.92% respectively. Conversely, WER dropped significantly in both cases, resulting in percent differences of 196.58% and 196.31% respectively.
The sad poetry sample has slightly different results. While with case differences were similar in the drop off observed with the funny poetry sample, without case resulted in an unusual 0.00% reading. We attribute this to a statistical anomaly, given the vast difference in language corpus. Thus, the DER percent difference for the with case observations is 22.67%, and the WER percent difference for the with case observations is 195.11%.
Experiments with CAMeLBERT SA Models
The four different sentiment analysis models provided by CAMeLBERT are shown below with Accuracy vs. Sentence bar plots and respective heatmaps to give visual emphasis for accuracy results. The sentence classifications were largely identified as neutral, and as such, they will be treated as the default label for each sentence in the given plots. If the classifications are different, it will be explicitly noted and discussed.
Experiment 1: CAMeLBERT Mix SA Model
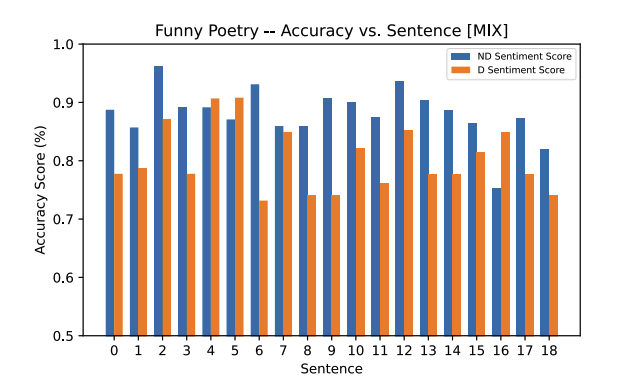
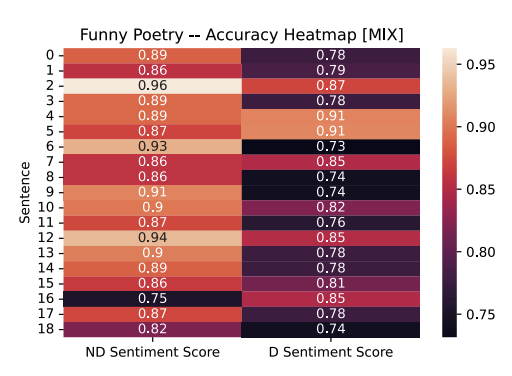
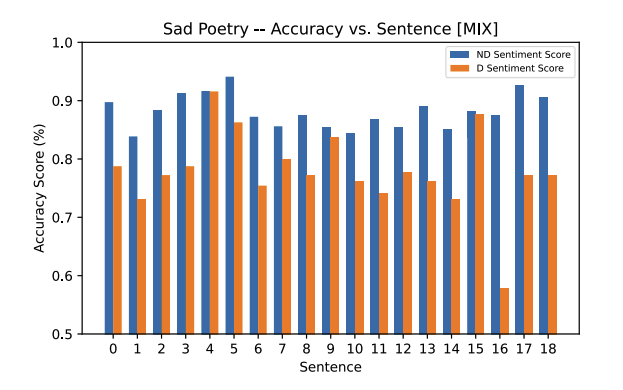
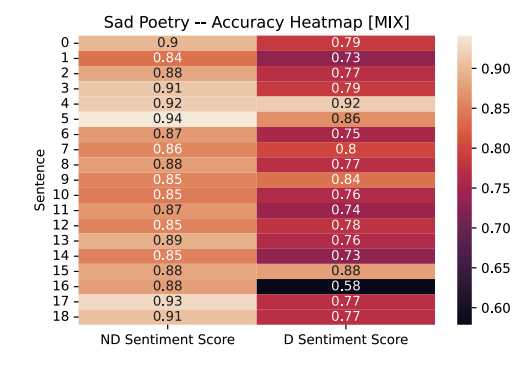
The neutral classifications, and the associated accuracy for those classifications in each poetry sample, is kept consistent according to the original hypothesis on this Mixed Arabic model. For the funny poetry, we expected the incorrect original classification of high accuracy for neutral to drop lower, and we observe these in the results collected in both the sad and funny poetry. The heatmaps show visually the decrease in percentage for each sentence.
A few outliers exist and should be noted. Specifically, sentences 4 and 5 in the funny poetry sample which had a minor increase in accuracy for the neutral classification. Additionally, in the sad poetry sample, sentence 4 had no statistically significant difference in accuracy before and after diacritization.
Experiment 2: CAMeLBERT DA SA Model
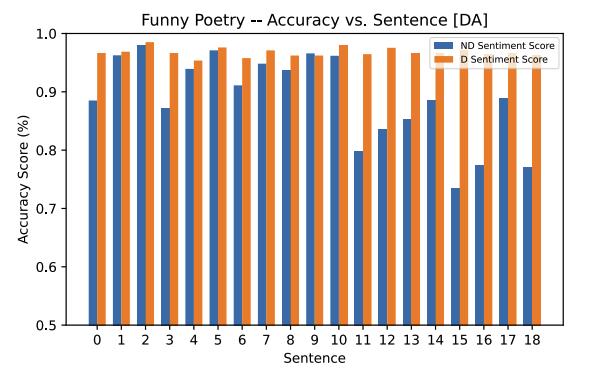
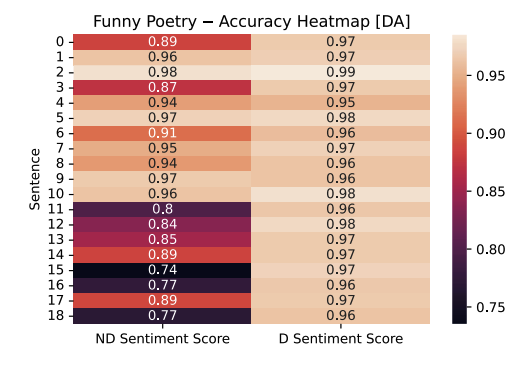
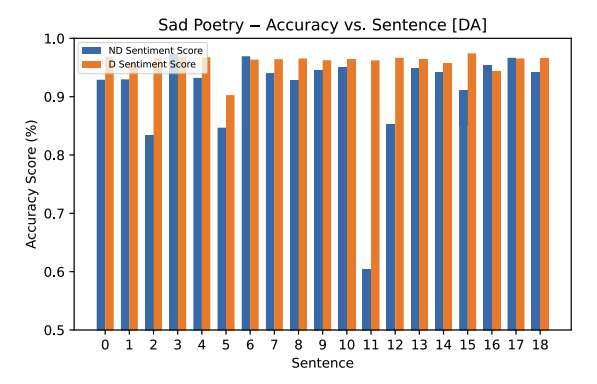
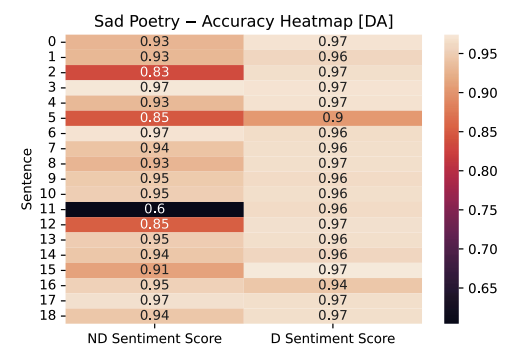
The Dialectal Arabic model has the reverse effect compared to the Mixed Arabic model. Here, we see diacritized accuracy increase for each of the sentences in the funny and sad poetry sample. A few outliers exist (where accuracy goes down with diacritization), but their accuracy difference is statistically insignificant and is not considered.
Another observation that stands out is the large difference in the funny poetry sample between non-diacritized and diacritized sentences from sentence 11 down to 18. This, we don’t believe is relevant/significant for our research question (as sentences were pulled randomly), but it is a noteworthy observation nonetheless. Additionally, sentence 11 in the sad poetry sample has the largest difference between its non-diacritized and diacritized version. This may lead to inquisition on whether certain words in Urdu are flagged falsely from the usage of an Arabic corpus.
Experiment 3: CAMeLBERT CA SA Model
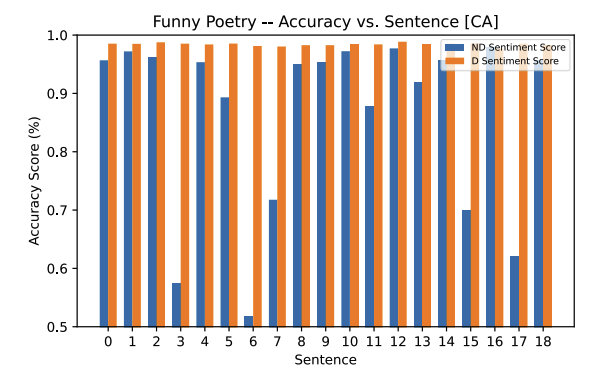
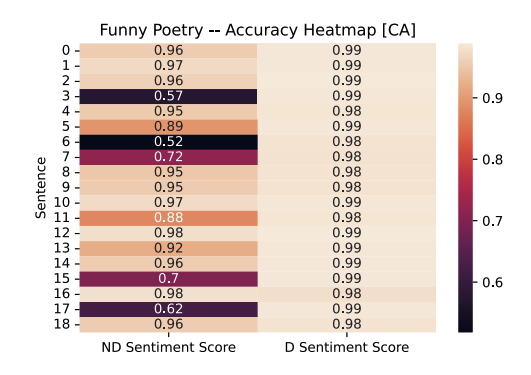
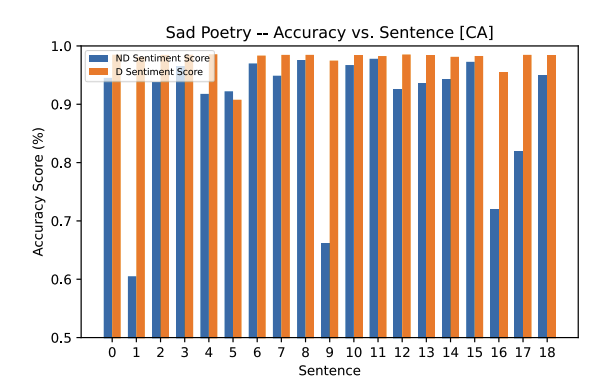
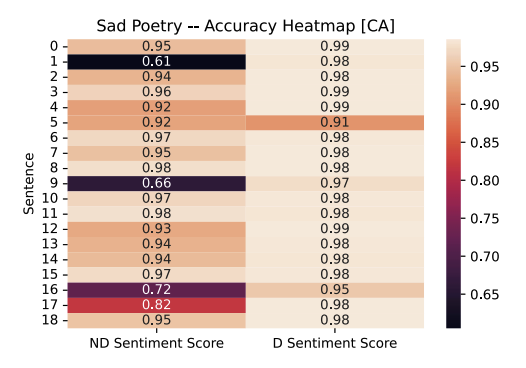
This is the first model so far that has had labels on sentences other than “neutral.” Sentence 7 had a “positive” label with 72% accuracy in the funny poetry sample. Sentences 9, 11, and 12 also had a “positive” label with 66%, 98%, and 93% respectively in the sad poetry sample. A “positive” label in the funny poetry sample was expected; although, it was unexpected from this Classical Arabic model as it tends to be largely archaic and reserved for religious texts. The poetry sample chosen does not seem to follow this linguistic style.
The three “positive” labels, especially sentences 11 and 12 with fairly high accuracy was something we expected from the archaic nature of the Classical Arabic model. As in, we expected incorrect predictions to be made.
Experiment 4: CAMeLBERT MSA SA Model
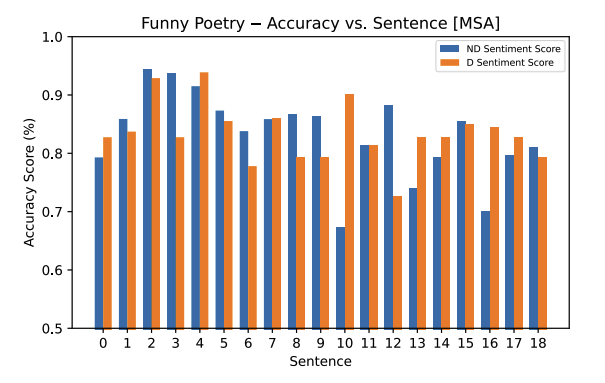
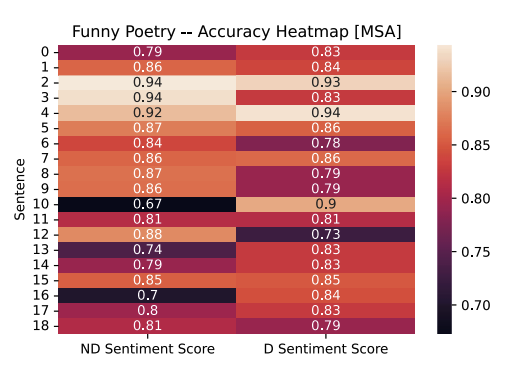
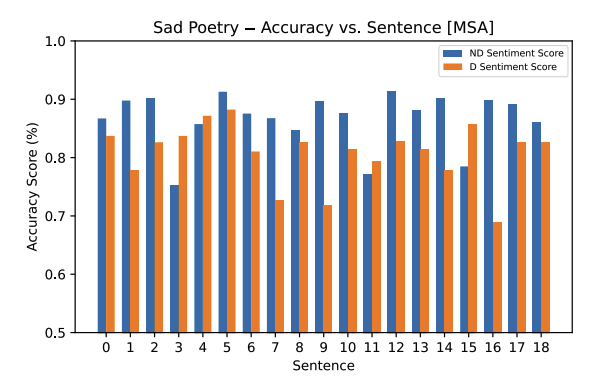
The Modern Standard Arabic model, similar to the Mixed Arabic model, performs as we expected. We observe notable decreases in accuracy from the “neutral” label, as they should’ve been explicitly either “negative” or “positive,” across all sentences in both the funny and sad poetry samples. There is one outlier in the sad poetry sample (sentence 2) where an incorrect “positive” label is generated with 90% accuracy. Additionally, sentence 10 in the funny poetry sample has an increase in accuracy for the “neutral” classification.
Discussion and Limitations
Poetry scrubbing did an adequate job at scrubbing poems from each funny and sad categorized page, but we were limited by the categorization of the poems on each page from the individual or group that categorized them. Therefore, there is a high level of subjectivity that enters this work that may limit/hinder results.
Diacritization posed a novel challenge as training the BERT Diacritizer model through numerous epochs was costly with the Jetson Nano hardware. Original training for the D3 model was 1000 epochs but was reduced to 100 to train in an adequate timeframe (8 hours). If the model was trained on the full 1000 epochs, it may have been more performant. This is one key change that we believe could be made to make the diacritization and inference process through the various sentiment analysis models better.
The WER and DER percentages were extraordinarily high post-diacritization. This was expected to some degree as the corpus used to train the models (Tashkeela) is based solely on Arabic and doesn’t “understand” Urdu linguistically. Nevertheless, the words with added case-endings had a lower percent difference from non-diacritized to diacritized representations. This may have linguistic meaning, due to word representations in Urdu, and may be a future direction for work. In general, Tashkeela tends to overfit the Urdu words in each given sentence to Arabic words by including sequences of diacritics which emulate Arabic phonology. This limited the work by changing the language to an almost uninterpretable state.
The Mixed Arabic (MIX) and Modern Standard Arabic (MSA) sentiment analysis models performed close to what we expected. The result was a majority of sentences giving a lower neutral classification after diacritization. Thus, we can conclude that these two models are less “neutral”, which should be expected as discrete results in relation to “positive” or “negative” should be observed. The limitation lies with the model on the opposite classification. As a reduction of “neutral” signifies “positive” or “negative,” it doesn’t give clear indication as to what the exact sentiment is for each poetry sample. Additionally, “neutral” scores were the main label attached to each non-diacritized sample input into the SA model (with some outliers discussed in more detail in Section 5.3 for each model). After diacritization, each SA model converged on a “neutral” value and all outlier labels were diminished. While “neutral” gave the basis success result as described earlier in this paragraph, it also contributes to the lack of uncertainty of the direct “positive” or “negative” result being established.
Conclusion and Future Work
With Urdu being a resource poor language, it is extremely hard for computers to be able to perform NLU-based sentiment analysis as the linguistic corpus state is underdeveloped. Additionally, lack of diacritics (short vowels), reduces word interpretability as meaning is often lost and must be inferred by the reader – a quality computers lack naturally. Although ambitious, poems represent a novel challenge for machine learning networks to accurately predict sentiment. For easier sentiment categorization based on discrete bounds (“positive” or “negative”), we scrubbed a poetry site’s categories for funny and sad poems.
By using an existing, well-researched, and robust Arabic corpus to diacritize Urdu poems, we gain diacritic representations of each poem sample. Despite many key limitations as noted in Section 6, this work showed that “neutral” scores for previously high accuracy are reduced in Mixed Arabic (MIX) and Modern Standard Arabic (MSA) models. This is what we expected indirectly as “neutral” should be reduced to better fit “positive” and “negative” for funny and sad poems respectively.
Future work largely revolves around one major criteria: Developing lexical resources for Urdu. First, similar to how Tashkeela has developed a robust Arabic corpus by parsing over 75 million words from written text and online text, a framework should be developed to automate and grow diacritization corpus state for Urdu. By doing so, it will allow Urdu to gain its own independent state and allow DER and WER to be reduced. An in-depth analysis of case versus no case endings may give further insight into reduction of DER and WER. Additionally, the sentiment analysis corpus state for Urdu is also poor. CAMeLBERT works well for Arabic, but it gives wanting results for Urdu. This makes sense as they are completely different languages despite similarity in script and some similarity in words.
While the previous paragraph outlines the major roadblocks and challenges that must be addressed in future work, some incremental steps could also be taken. First, fine-tuning the Tashkeela model to run through more epochs and adjusting parameters to fit that of Urdu, may help in overall diacritization accuracy. Additionally, usage of a different sample framework may give sentiment analysis gains. More specifically, poems are still too challenging, as shown from the results, to properly categorize into “positive” and “negative” labels. By choosing more colloquial text, it may help in inference through existing models.
References
[1] Vaswani, A., et al. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems. pp. 6000–6010. (Long Beach, California, 2017).
[2] Mourri, A. and Kaiser, Ł. Natural Language Processing with Attention Models. https://www.coursera.org/lecture/attention-models-in-nlp/transformers-vs-rnns-glNgT (March 21, 2022).
[3] Belinkov, Y. and Glass, J. Arabic Diacritization with Recurrent Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. pp. 2281–2285. (Lisbon, Portugal, 2015).
[4] Azmi, A., Alnefaie, R., and Aboalsamh, H. Light Diacritic Restoration to Disambiguate Homographs in Modern Arabic Texts. ACM Transactions on Asian and Low-Resource Language Information Processing. Volume 21. pp. 1–14.
[5] Habash, N., Soudi, A., and Buckwalter, T. On Arabic Transliteration. In Arabic Computational Morphology (Springer. Dordrecht, Netherlands. 2007) pp. 15–22.
[6] Jetson Nano Developer Kit. https://developer.nvidia.com/embedded/jetson-nano-developer-kit (March 22, 2022).
[7] Weninger, F., Bergmann, J., and Schuller, B. Introducing CURRENNT: the Munich open-source CUDA RecurREnt neural network toolkit. Journal of Machine Learning Research. Volume 16. pp. 547–551. 2015.
[8] Inoue, Go., et al. The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models. ArXiv. Volume abs/2103.06678. 2021.
[9] Zerrouki T. and Balla A. Tashkeela: Novel corpus of Arabic vocalized texts, data for auto-diacritization systems. Data in Brief. Volume 11. pp. 147–151. 2017.
[10] Darwish, K., et al. Arabic Diacritic Recovery Using a Feature-Rich BiLSTM Model. Transactions on Asian and Low-Resource Language Information Processing. Volume 20. pp. 1–18.
This project was completed as part of HCI 575 (Human-Computer Interaction) at Iowa State University.